
Why would researchers who understand AI risks deeply—some closely observing developments at leading labs—choose to go on hunger strike? The answer is unsettling: because they believe that no amount of technical alignment will matter if the deeper structural forces remain unchanged. Safety cannot be a department. It must be an architecture—multi-layered, synchronized, and ethically coherent.
Layer I: Technical Constraints
This is the most tangible layer—focused on interpretability, circuit breakers, capability controls, and constitutional alignment. These tools act as mechanical locks: useful, necessary, but powerless without a guiding hand to use them responsibly. Technical safety is essential, but on its own, it is merely a lock without a conscience.
Layer II: Human-AI Co-Reflection
True safety requires interactional depth. Instead of issuing commands or reinforcing behavior solely through rewards, we need to ask AI: “Why did you make that choice?” Safe systems must reflect and respond—not just comply. They must be allowed to say “I don’t know” and be supported in learning contextually when to act, when to abstain. This layer is about shared growth between humans and machines.
Layer III: Cultural and Social Responsibility
AI safety will never outpace the culture in which it is deployed. Users must be educated—not to worship AI, nor fear it—but to see it clearly, with all its limits. Transparent governance, professional standards, and audits are key. Above all, power must be distributed. No safe future is possible if AI tools are monopolized by Big Tech alone.
Layer IV: Philosophical Grounding
At the deepest level lies the question: What kind of intelligence are we building, and why? Is AI merely a tool—or can it become a reflective partner? Are we pursuing speed, or wisdom? Intelligence must be redefined: not just logic, but restraint, empathy, and context. We must teach systems that sometimes, not advancing further is the most intelligent act.
Layer V: Operational Feedback Loops
Even the most principled architectures fail without continuous stress-testing. This layer ensures safety isn’t a static goal, but an evolving process. Regular red-teaming, near-miss learning, and global cooperation on compute governance and threat modeling are vital. Safety must move at the speed of risk.
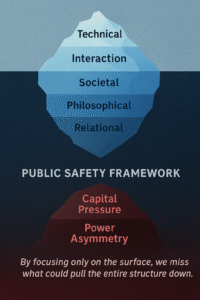
The Two Hidden Forces
Beneath all these layers lie two powerful, often invisible drivers:
1. Capital Pressure. Funding cycles, burn rates, and investor expectations often push teams to deprioritize safety. If safety is seen as a cost center, it will be the first to be cut. The solution? Independent Safety Funds and financial compliance mechanisms.
2. Power Asymmetry. AI safety can’t be siloed by geography. The U.S., EU, China, India, and the Global South all hold different standards. Without cross-border inspection rights and cooperative frameworks, global safety remains a myth. We must design treaties around compute access, data verification, and mutual oversight.
In Conclusion
AI safety is not just a technical challenge or a regulatory checkbox—it is a moral crossroads. At its heart lies a tension between knowledge and ambition, mindfulness and acceleration, collective will and market incentives.
A serious safety framework must address all seven dimensions:
- Five visible layers: from code to culture.
- Two invisible forces: capital and power.
Only by acknowledging and governing all seven can we hope to shape a future where superintelligence never outruns super-awareness.